db = {}
before (done) ->
# Create the data base connection
db = new couchbase.Connection
host: 'localhost:8091’
bucket: ‘test’
# Create the user we are looking for
wantedUser = utils.support.get_user_args()
wantedUserId = "user:#{utils.support.random.number()}"
# Create the requester user with admin rights
adminUser = utils.support.get_user_args
rights: ['admin']
adminUserId = "user:#{utils.support.random.number()}"
# Create the requester user without the admin rights
hackerUser = utils.support.get_user_args()
hackerUserId = "user:#{utils.support.random.number()}"
# Insert 1st user in the data base
db.add wantedUserId, wantedUser, (err, results) ->
# Insert 2nd user in the data base
db.add adminUserId, adminUser, (err, results) ->
# Insert 3rd user in the data base
db.add hackerUserId, hackerUser, (err, results) ->
done()
I would to know if there is a solution to get something like that instead:
Even though there is no direct support in the SDK you can use the async library to do what you want. As a small example I create a little script which inserts 100 documents in parallel. Depending on your needs you should also look into async series and so on.
var couchbase = require("couchbase")
var async = require("async")
var db = new couchbase.Connection({})
// create insert function which expects just a callback
function insertFormObject(object) {
return function (cb) {
db.set(object._id, object.value, cb)
}
}
// create array of inserts
var documents = [
{ _id: “mykey-0”, value: { iam: “adoc” } },
{ _id: “mykey-1”, value: { iam: “adoc” } },
{ _id: “mykey-2”, value: { iam: “adoc” } },
{ _id: “mykey-3”, value: { iam: “adoc” } }
]
var inserts = documents.map(function(o) { return insertFormObject(o) })
// run all inserts in parallel
async.parallel(inserts, function(err) {
if(err) new Error(err);
db.shutdown();
})
As the SDK provides a number of options for the various mutation operations, we avoided providing bulk mutation operations, and instead opted to allow the developers to build their own bulk mutation operations which are more application specific. Note that the SDK performs internal batching using the Node.js event loop and thus dispatching operations simultaneously in Node.js is not any faster than we could do it internally (see the getMulti implementation to see what I mean).
In a serverless environment, the desire to batch save explicitly is more about stability than performance.
I believe providing a batch save solution may need to be revisited due to realities one must consider when calling any data-store from a function hosted in a serverless environment. The issue becomes more prevalent when the above is implemented from within a loop.
The issue which drove me to this topic involves a formerly stable function invoking a “fire-and-forget” save to Couchbase, from within a loop from within an AWS Lambda function. A subtle addition was apparently just enough to push the stability of the solution into instability. The solution is throwing client-side timeouts regularly.
Although I am confident I will be able to improve my implementation sufficiently to restore the function to its previous stability, the manner by which this will be achieved will be more laborious than it needs to be, IMHO.
Collecting a batch of writes to buffer is imminently faster than making a request over the wire to a remotely hosted database within a loop. When written explicitly, control is maintained when and how. Ideally, this would be after the loop has resolved. The SDK cannot know when the end of the batch has been reached before its sends the batch unless it is set ahead of time. This means it must be assessing conditions dynamically. Stateless|serverless makes this much more difficult.
For these reasons above, I hope Couchbase reconsiders how batching may be more intuitive.
I think you missed my earlier point here. The Node.js SDK does in fact batch requests together into batched writes to the network (as you mentioned, this is almost always faster). The way we do this is very specific to Node.js, and the outcome is that our batches are as big as they can reasonably be (ie: there is no room for improved performance from explicitly delineating the batch boundaries).
The SDK cannot know when the end of the batch has been reached before its sends the batch unless it is set ahead of time.
This is not actually true for Node.js. As you are probably aware, the Node.js SDK operates around the concept of an event loop (which is implemented in libuv). That is, the libuv event loop observes some event occurring outside your application (such as data being received from the network), and this invokes an event handler in Node.js from within the event loop. The event loop runs in a … loop … between waiting for an event, and processing any events that have occurred during the wait (see: Design overview - libuv documentation). In the Node.js SDK, we hook into the event loop processing mechanism such that our underlying network writes are held in our internal buffers as long as we are still in the middle of the event loop (and we have room in the buffer), at the end of a particular event loop iteration (or when our internal buffers fill up), the SDK will flush any pending writes out to the network in a large batch. This has the effect that in your application, executing a loop of operations does not incur a write per operation, but rather only executes a couple of batched writes (based on the the internal buffer size). For a more concrete example:
app.get('/get_all_users', (req, resp) => {
// This code block is entered from within the event handler for HTTP.
// The HTTP library would be internally receiving HTTP data, and once
// a full HTTP request is received, it forwards that data to your handler
// here.
var users = [];
// Start a loop performing 10,000 operations all
for (var i = 0; i < 10000; ++i) {
// Here we execute a GET operation, but this command does not actually
// write to the network, rather it writes to an internal buffer within
// libcouchbase (our underlying protocol implementation). After a
// certain number of operations have been received, the buffer gets
// flushed to the network and the process continues batching into
// the newly empty internal buffer.
bucket.get('user_'+i, (err, res) => {
users.push(res);
// Check if all the user operations have completed.
if (users.length === 10000) {
res.send(users);
}
});
}
// Now that all the looping is done, we will have items sitting in
// our buffer that needs to be flushed to the network, once this
// function returns we will eventually return to the libuv event
// loop, and this completion of an iteration of our event loop will
// trigger an 'end-of-iteration' event back to libcouchbase from
// libuv which causes the buffer to be flushed.
});
In the opening of my post I predicated the scope of my concerns with the qualifier "In a serverless environment". It wasn’t that I missed your point. Any SDK performing in a short-lived, stateless, serverless environment will likely require adjustments for a number of well-documented reasons.
I owe you the code to provide context.
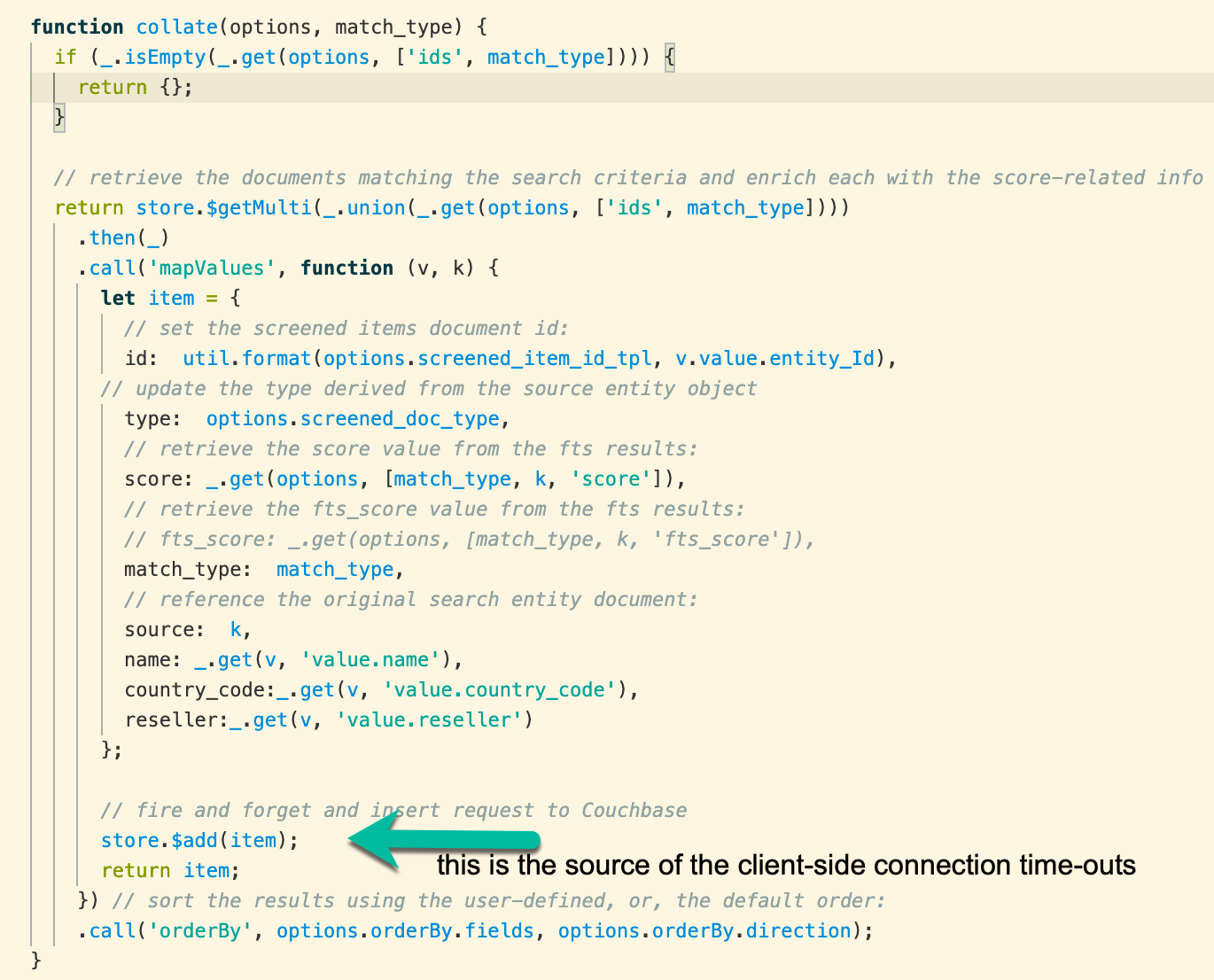
Here is the now (not previously) problematic serverless function implemented
I don’t see how the example or the explanation provided may be applied to a natively non-static, non-durable, short-lived process of a serverless function. There is no Node event-loop occurring outside the application, only within it and only within the confines of the beginning and ending of the functions execution context and the configured TTL. All Node events must complete before the function returns results or times-out.
The example you provided illustrates an http get request from within a standard hosted Nodejs server. The challenge I am facing relates to looping inserts to Couchbase from within a stateless, serverless environment, for which the durability of a connection is not guaranteed. This isn’t to say the connection pooling isn’t maintained, it only means the pooling is not as consistent as it would be in a durably-hosted Node service process. Attenuation in the connection might be just enough to open and close access to the connection pool long enough to create a client-side time-out when repeated requests are attempted on an external, connected resource.
In your example code, there will be only one batched write to the network (containing many insert operations) performed, no matter the number of items fetched from the $getMulti (unless $getMulti generates a massive number of results). The event loop I am referring to is an internal Node.js concept and not visible to the application, and exists whether the application is deployed in a serverless environment or not (since even in a serverless environment, there is still a server, but the management of them is hidden).
Edit:
The post was originally talking about batching of INSERT operations, but it does seem like it’s possible you’re more discussing how to configure Couchbase to behave best in a serverless environment where Couchbase’s persistent connections to the database can actually be hurtful rather than helpful?
Additionally, just to add some clarity here, the following is more or less the behaviour that would be exhibited by your application w.r.t. the event loop and the network writes:
Your application invokes collate() somehow.
Your application invokes $getMulti from collate, which eventually invokes cb::getMulti.
getMutli schedules a bunch GET operations, which get written through libcouchbase into its internal send buffer.
Your application continues processing, eventually leaving whatever event handler triggered the call to collate() in the first place.
The SDK detects the end of the event loop iteration and flushes libcouchbase’s writes (which contains a the batched GET operations).
A GET response is received, this goes into a queue waiting for all the individual GET operations which made up the getMulti call to complete (this is the getMulti implementation).
Eventually all the GET responses are received, which triggers the invocation of the handler that was provided to getMulti (this is invoked from the handler of the final GET response being received).
The getMulti handler invokes mapValues which maps each key/value and this eventually calls $add which calls cb::insert().
The cb::insert call tells libcouchbase to write an insert operation into its send buffer. This happens over and over for each mapped value. nothing is written to the network yet.
Eventually the application calls bubble all the way back up to the handler from that ‘final GET of the getMulti’.
The event loop iteration completes, causing the SDK to flush libcouchbases send buffer as a single write (containing the batched INSERT operations).
Correct. Serverless only. No disagreement with any of the knowledge of standard Node event-loop or how couchbase queues writes in the SDK.
I sought how to adjust your illustration to serverless context, which I believe you have done.
My point was anything adding to latency in an iterative sequence, in a serverless context, which attempts writes to any external resource, could result in the queued requests to timeout.
Between the time I posted and the time you replied, I identified an artifact in my code which could cause delay in execution. It appears by removing this artifact duplicate key check on the $add call and optimizing how each item in the loop is transformed and set was more than enough to eliminate the client-side timeouts. The stability has been restored and the performance has been boosted. No more timeouts.
I have since figured out how to dynamically build a standard N1QL UPSERT query which allows me to SELECT into the UPSERT using the Nodejs SDK 2.6.9. works magnificently.