CouchBase version: 6.5.1 build 6299, run in GCP.
Today we suddenly started to experience a strange behavior of the num_mutations_to_index on our single FTS index: it fluctuates randomly between zero and 6 millions (we only have a quite moderate mutation rate of several dozens per second on a given bucket) for several hours. At the same time an index is constantly above 94% ready (100% ready most of the time).
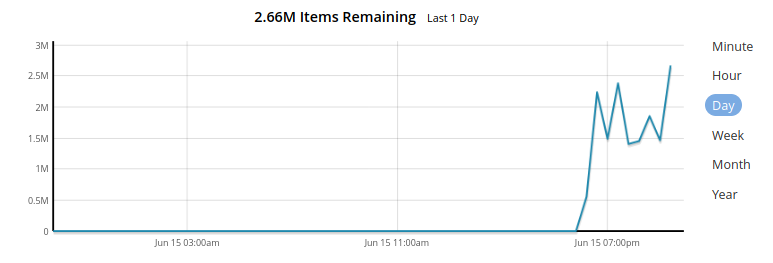
This seems strange, so I also attach a random stats snapshot (passed through jq):
{
"batch_bytes_added": 15939907503,
"batch_bytes_removed": 15939805450,
"curr_batches_blocked_by_herder": 18446744073709552000,
"device-meta:device-meta-devices-list-v1:avg_grpc_internal_queries_latency": 444.864718,
"device-meta:device-meta-devices-list-v1:avg_grpc_queries_latency": 8.486374,
"device-meta:device-meta-devices-list-v1:avg_internal_queries_latency": 3.248349,
"device-meta:device-meta-devices-list-v1:avg_queries_latency": 3.488489,
"device-meta:device-meta-devices-list-v1:batch_merge_count": 0,
"device-meta:device-meta-devices-list-v1:doc_count": 13626,
"device-meta:device-meta-devices-list-v1:iterator_next_count": 0,
"device-meta:device-meta-devices-list-v1:iterator_seek_count": 0,
"device-meta:device-meta-devices-list-v1:last_access_time": "2022-06-15T18:22:05.486+00:00",
"device-meta:device-meta-devices-list-v1:num_bytes_live_data": 0,
"device-meta:device-meta-devices-list-v1:num_bytes_used_disk": 11908801,
"device-meta:device-meta-devices-list-v1:num_bytes_used_disk_by_root": 2567877,
"device-meta:device-meta-devices-list-v1:num_files_on_disk": 238,
"device-meta:device-meta-devices-list-v1:num_mutations_to_index": 713142,
"device-meta:device-meta-devices-list-v1:num_persister_nap_merger_break": 3764362,
"device-meta:device-meta-devices-list-v1:num_persister_nap_pause_completed": 6569687,
"device-meta:device-meta-devices-list-v1:num_pindexes_actual": 21,
"device-meta:device-meta-devices-list-v1:num_pindexes_target": 21,
"device-meta:device-meta-devices-list-v1:num_recs_to_persist": 0,
"device-meta:device-meta-devices-list-v1:num_root_filesegments": 21,
"device-meta:device-meta-devices-list-v1:num_root_memorysegments": 0,
"device-meta:device-meta-devices-list-v1:reader_get_count": 0,
"device-meta:device-meta-devices-list-v1:reader_multi_get_count": 0,
"device-meta:device-meta-devices-list-v1:reader_prefix_iterator_count": 0,
"device-meta:device-meta-devices-list-v1:reader_range_iterator_count": 0,
"device-meta:device-meta-devices-list-v1:timer_batch_store_count": 0,
"device-meta:device-meta-devices-list-v1:timer_data_delete_count": 1024,
"device-meta:device-meta-devices-list-v1:timer_data_update_count": 7387046,
"device-meta:device-meta-devices-list-v1:timer_opaque_get_count": 7385082,
"device-meta:device-meta-devices-list-v1:timer_opaque_set_count": 7383290,
"device-meta:device-meta-devices-list-v1:timer_rollback_count": 0,
"device-meta:device-meta-devices-list-v1:timer_snapshot_start_count": 7381525,
"device-meta:device-meta-devices-list-v1:total_bytes_indexed": 1510334272,
"device-meta:device-meta-devices-list-v1:total_bytes_query_results": 8241,
"device-meta:device-meta-devices-list-v1:total_compaction_written_bytes": 478867709080,
"device-meta:device-meta-devices-list-v1:total_compactions": 0,
"device-meta:device-meta-devices-list-v1:total_grpc_internal_queries": 135870,
"device-meta:device-meta-devices-list-v1:total_grpc_queries": 59783,
"device-meta:device-meta-devices-list-v1:total_grpc_queries_error": 0,
"device-meta:device-meta-devices-list-v1:total_grpc_queries_slow": 16,
"device-meta:device-meta-devices-list-v1:total_grpc_queries_timeout": 0,
"device-meta:device-meta-devices-list-v1:total_grpc_request_time": 507340926713,
"device-meta:device-meta-devices-list-v1:total_internal_queries": 22858,
"device-meta:device-meta-devices-list-v1:total_queries": 10,
"device-meta:device-meta-devices-list-v1:total_queries_error": 4,
"device-meta:device-meta-devices-list-v1:total_queries_slow": 0,
"device-meta:device-meta-devices-list-v1:total_queries_timeout": 0,
"device-meta:device-meta-devices-list-v1:total_request_time": 35254836,
"device-meta:device-meta-devices-list-v1:total_term_searchers": 1356470,
"device-meta:device-meta-devices-list-v1:total_term_searchers_finished": 1356470,
"device-meta:device-meta-devices-list-v1:writer_execute_batch_count": 0,
"device-meta:device-meta-devices-list:avg_grpc_internal_queries_latency": 0,
"device-meta:device-meta-devices-list:avg_grpc_queries_latency": 0,
"device-meta:device-meta-devices-list:avg_internal_queries_latency": 0,
"device-meta:device-meta-devices-list:avg_queries_latency": 21.700223,
"device-meta:device-meta-devices-list:batch_merge_count": 0,
"device-meta:device-meta-devices-list:doc_count": 0,
"device-meta:device-meta-devices-list:iterator_next_count": 0,
"device-meta:device-meta-devices-list:iterator_seek_count": 0,
"device-meta:device-meta-devices-list:last_access_time": "",
"device-meta:device-meta-devices-list:num_bytes_live_data": 0,
"device-meta:device-meta-devices-list:num_bytes_used_disk": 0,
"device-meta:device-meta-devices-list:num_bytes_used_disk_by_root": 0,
"device-meta:device-meta-devices-list:num_files_on_disk": 0,
"device-meta:device-meta-devices-list:num_mutations_to_index": 0,
"device-meta:device-meta-devices-list:num_persister_nap_merger_break": 0,
"device-meta:device-meta-devices-list:num_persister_nap_pause_completed": 0,
"device-meta:device-meta-devices-list:num_pindexes_actual": 0,
"device-meta:device-meta-devices-list:num_pindexes_target": 0,
"device-meta:device-meta-devices-list:num_recs_to_persist": 0,
"device-meta:device-meta-devices-list:num_root_filesegments": 0,
"device-meta:device-meta-devices-list:num_root_memorysegments": 0,
"device-meta:device-meta-devices-list:reader_get_count": 0,
"device-meta:device-meta-devices-list:reader_multi_get_count": 0,
"device-meta:device-meta-devices-list:reader_prefix_iterator_count": 0,
"device-meta:device-meta-devices-list:reader_range_iterator_count": 0,
"device-meta:device-meta-devices-list:timer_batch_store_count": 0,
"device-meta:device-meta-devices-list:timer_data_delete_count": 0,
"device-meta:device-meta-devices-list:timer_data_update_count": 0,
"device-meta:device-meta-devices-list:timer_opaque_get_count": 0,
"device-meta:device-meta-devices-list:timer_opaque_set_count": 0,
"device-meta:device-meta-devices-list:timer_rollback_count": 0,
"device-meta:device-meta-devices-list:timer_snapshot_start_count": 0,
"device-meta:device-meta-devices-list:total_bytes_indexed": 0,
"device-meta:device-meta-devices-list:total_bytes_query_results": 48287005,
"device-meta:device-meta-devices-list:total_compaction_written_bytes": 0,
"device-meta:device-meta-devices-list:total_compactions": 0,
"device-meta:device-meta-devices-list:total_grpc_internal_queries": 0,
"device-meta:device-meta-devices-list:total_grpc_queries": 0,
"device-meta:device-meta-devices-list:total_grpc_queries_error": 0,
"device-meta:device-meta-devices-list:total_grpc_queries_slow": 0,
"device-meta:device-meta-devices-list:total_grpc_queries_timeout": 0,
"device-meta:device-meta-devices-list:total_grpc_request_time": 0,
"device-meta:device-meta-devices-list:total_internal_queries": 0,
"device-meta:device-meta-devices-list:total_queries": 11822,
"device-meta:device-meta-devices-list:total_queries_error": 1,
"device-meta:device-meta-devices-list:total_queries_slow": 8,
"device-meta:device-meta-devices-list:total_queries_timeout": 0,
"device-meta:device-meta-devices-list:total_request_time": 256567906899,
"device-meta:device-meta-devices-list:total_term_searchers": 0,
"device-meta:device-meta-devices-list:total_term_searchers_finished": 0,
"device-meta:device-meta-devices-list:writer_execute_batch_count": 0,
"num_bytes_used_ram": 9268044600,
"pct_cpu_gc": 0.0015641345992357118,
"tot_batches_flushed_on_maxops": 0,
"tot_batches_flushed_on_timer": 23465069,
"tot_bleve_dest_closed": 19,
"tot_bleve_dest_opened": 40,
"tot_grpc_listeners_closed": 0,
"tot_grpc_listeners_opened": 1,
"tot_grpc_queryreject_on_memquota": 23,
"tot_grpcs_listeners_closed": 0,
"tot_grpcs_listeners_opened": 1,
"tot_http_limitlisteners_closed": 0,
"tot_http_limitlisteners_opened": 1,
"tot_https_limitlisteners_closed": 0,
"tot_https_limitlisteners_opened": 1,
"tot_queryreject_on_memquota": 0,
"tot_remote_grpc": 1330278,
"tot_remote_grpc_tls": 0,
"tot_remote_http": 439082,
"tot_remote_http2": 0,
"total_gc": 43695,
"total_queries_rejected_by_herder": 23
}
I suspect there could be some integer overflow in the counter code:
At least one counter above has grown beyond the unit64 max value.
Could you take a look and tell if this is something expected or unexpected but has a known workaround. We currently rely onto this metric to be close to zero, so we can monitor any excessive lag in the index performance.


