I’m currently testing large push replications (~75mb) on CBLite for Android and running into some server side problems. The push gets approximately 3/5ths of the way through, and then looses connection to the server. Following the lost connection on the app, connections to the Couchbase management console and via SSH directly into the Ubuntu instance also fail. I should add that this continues indefinitely until I restart the instance on AWS (the longest I’ve waited was roughly three days over a weekend).
The only explanation I can think of is that a t2.micro instance is too small to handle any sort of a heavy load. I read through some forum posts that indicated that that was, indeed the problem, but I wanted to get confirmation. I’ll update this with logs as soon as a restart the server.
I don’t host my CB cluster on AWS but would strongly advise to use at least 4GB for testing. As soon as you have got users I’d suggest at least 8GB for each node, and to use several nodes, of course.
That’s a small instance, but the system should never behave like that, so something is going wrong and it’s probably worth digging into it. Using a bigger instance will probably just delay the problem or require a higher load to reproduce rather than solving it completely.
That sounds like the entire OS is either crashing or the sync gateway process is using up all the available system resources (possibly memory or file handles) and causing the system to essentially come to a halt.
I’d recommend adding some monitoring while you are running sync gateway to see where the system is getting into an unhealthy state. Which version of Sync Gateway are you running? In the upcoming Sync Gateway 1.3 release, it will ship with sg_collect_info. It might be possible to run that tool standalone on older versions of sync gateway, since it’s just a python script.
My hunch is that sync gateway is using up all the resources because I frequently have to restart it when I don’t loose access to the server. I’ll try tuning the max no. of file descriptors and update you when I have.
I am running Couchbase Server on the same instance. The idea was work with a bare-bones instance until we moved to production.
So I couldn’t get sg_collect_info to work (got the error: File “sgcollect_info”, line 24, in from tasks import CbcollectInfoOptions), but here’s the last few lines of the log file before the sync failed:
2016-07-13T13:04:03.884Z CRUD+: Invoking sync on doc "86f7737c-2076-4fde-8986-a235348c36b6" rev 1-8c3b6db40435777465f841fa5e5342c4 2016-07-13T13:04:03.884Z CRUD: Stored doc "86f7737c-2076-4fde-8986-a235348c36b6" / "1-8c3b6db40435777465f841fa5e5342c4" 2016/07/13 13:04:04 Unable to decode response unexpected EOF 2016/07/13 13:04:04 Trying with http://172.30.0.187:8091/pools/default/bucketsStreaming/default 2016/07/13 13:04:04 HTTP request returned error Get http://172.30.0.187:8091/pools/default/bucketsStreaming/default: dial tcp 172.30.0.187:8091: getsockopt: connection refused 2016-07-13T13:04:04.655Z WARNING: Bucket Updater for bucket default returned error: Get http://172.30.0.187:8091/pools/default/bucketsStreaming/default: dial tcp 172.30.0.187:8091: getsockopt: connection refused -- base.GetCouchbaseBucket.func1() at bucket.go:469 2016-07-13T13:04:04.655Z WARNING: Lost TAP feed for bucket default, with error: Get http://172.30.0.187:8091/pools/default/bucketsStreaming/default: dial tcp 172.30.0.187:8091: getsockopt: connection refused -- rest.(*ServerContext)._getOrAddDatabaseFromConfig.func1() at server_context.go:646 2016-07-13T13:04:04.655Z CRUD: Taking Database : miti_health, offline 2016-07-13T13:04:04.657Z CRUD: Waiting for all active calls to complete on Database : miti_health 2016-07-13T13:04:04.908Z Changes+: Notifying that "default" changed (keys="{*}") count=330 2016-07-13T13:04:04.992Z Changes+: Notifying that "default" changed (keys="{*}") count=331 2016-07-13T13:04:04.993Z Changes+: Notifying that "default" changed (keys="{*}") count=332 2016-07-13T13:04:04.995Z Changes+: Notifying that "default" changed (keys="{*}") count=333 2016-07-13T13:04:05.007Z Changes+: Notifying that "default" changed (keys="{*}") count=334 2016-07-13T13:04:05.011Z Changes+: Notifying that "default" changed (keys="{*}") count=335 2016-07-13T13:04:05.012Z Changes+: Notifying that "default" changed (keys="{*}") count=336 2016-07-13T13:04:45.232Z CRUD: Database : miti_health, is offline 2016/07/13 13:04:45 Bucket Updater exited with err Get http://172.30.0.187:8091/pools/default/bucketsStreaming/default: dial tcp 172.30.0.187:8091: getsockopt: connection refused 2016-07-13T13:04:45.234Z HTTP: #119: --> 503 DB is currently under maintenance (34841.3 ms) 2016-07-13T13:04:45.234Z HTTP: #118: --> 503 DB is currently under maintenance (39835.0 ms) 2016-07-13T13:04:48.660Z HTTP: #120: --> 503 DB is currently under maintenance (6.4 ms) 2016-07-13T13:04:50.650Z HTTP: #121: --> 503 DB is currently under maintenance (0.0 ms) 2016-07-13T13:04:55.868Z HTTP: #122: --> 503 DB is currently under maintenance (0.0 ms) 2016-07-13T13:05:00.172Z HTTP: #123: --> 503 DB is currently under maintenance (0.0 ms) 2016-07-13T13:05:08.266Z HTTP: #124: --> 503 DB is currently under maintenance (0.1 ms) 2016-07-13T13:05:17.703Z HTTP: #125: --> 503 DB is currently under maintenance (0.1 ms) 2016-07-13T13:05:25.968Z HTTP: #126: --> 503 DB is currently under maintenance (0.0 ms) 2016-07-13T13:06:27.926Z HTTP: #127: --> 503 DB is currently under maintenance (4.3 ms) 2016-07-13T13:06:27.933Z HTTP: #128: --> 503 DB is currently under maintenance (0.0 ms) 2016-07-13T13:06:32.606Z HTTP: #129: --> 503 DB is currently under maintenance (0.0 ms) 2016-07-13T13:06:32.607Z HTTP: #130: --> 503 DB is currently under maintenance (0.0 ms) 2016-07-13T13:06:41.443Z HTTP: #131: --> 503 DB is currently under maintenance (0.0 ms) 2016-07-13T13:06:41.445Z HTTP: #132: --> 503 DB is currently under maintenance (0.0 ms) 2016-07-13T13:06:58.173Z HTTP: #133: --> 503 DB is currently under maintenance (0.1 ms) 2016-07-13T13:06:58.175Z HTTP: #134: --> 503 DB is currently under maintenance (0.0 ms)
Following this all replications failed until I restarted sync gateway.
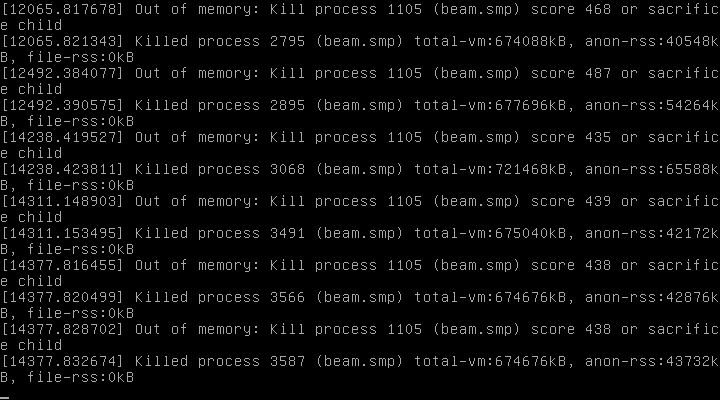
When I tried restarting I this error: -bash: fork: Cannot allocate memory.
My hypothesis is that Sync Gateway is using up 100% of my instance’s RAM, which is what is crashing the Couchbase server. When I restart Sync Gateway it clears everything in memory and replications proceed correctly. Does that sound right?
If you’re running Sync Gateway and Couchbase Server together on a t2.micro, then I’m sure you’re just hitting the limits of what you can do on that instance. Even for development I expect you’ll need a minimum of 4GB of RAM.