Hi gurus!.
I'm starting to use couchbase (for testing right now) for a project that will be handling around 40 millions documents. This is the environment:
2 servers: 4 CPUs, 26 GB RAM (each)
Ubuntu 14.04 LTS, Couchbase 4.5.0-2601 ED
I'm using upsert from Java SDK to load the data from csv. After around 20 millions documents, I get an Exception TemporaryFailure, I made some modification to the code and wait some time and retry the upsert when the exception appears. But when the program retries I see high CPU Load and I get the exception again.
Do you think that it is a hw problem (I need more capacity) or can I solve the issue by other way?
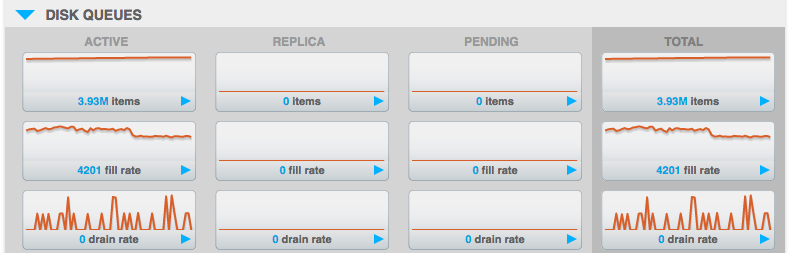
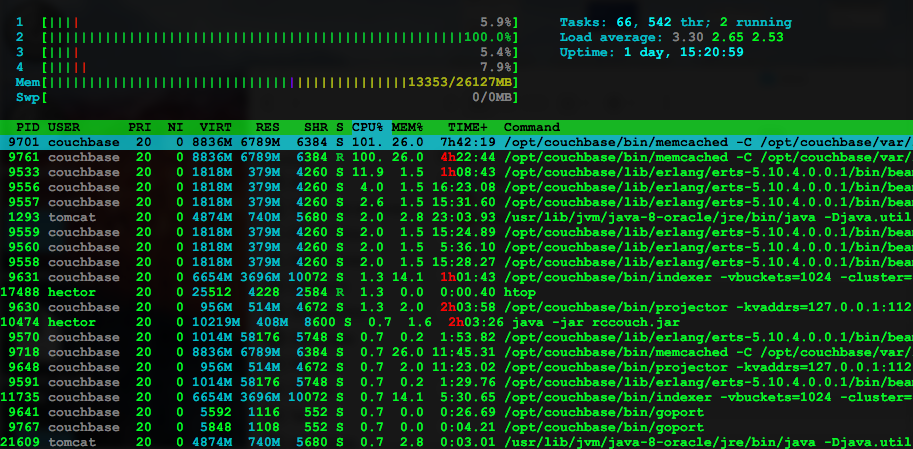
Here some printscreen before and after the issue.
CPU Before:

CPU After:

OPS Before:

OPS After:

HTOP Before:
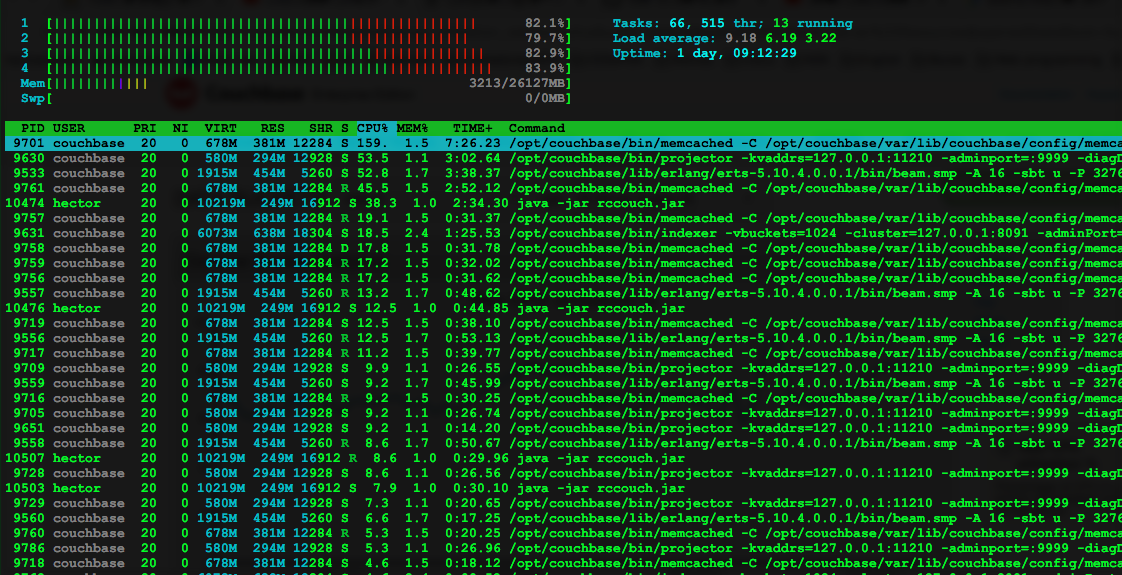
HTOP After:
Really basic code to load the data:
Observable
.from(reader)
.map(
csvRow → {
linea++;
JsonObject object = JsonObject.create();
object.put(“type”, tabla.toLowerCase());
object.put(“rc”, rc.toUpperCase());
try {
for (int j = 0; j < line.length; j++) {
setValor(object, campos[j], csvRow[j], tipos[j]);
}
} catch (Exception e) {
System.out.println(e.getMessage() + " en archivo: " + archivo + System.getProperty(“line.separator”) + “–> Linea: " + linea + " <–”);
}
if (!tabla.toLowerCase().equals(“utp_common_objects”)) {
return JsonDocument.create(UUID.randomUUID().toString() + new Random().nextInt(100), object);
} else {
return JsonDocument.create(csvRow[0], object);
}
}
)
.subscribe(document →
{
for (int i = 0; i < 6; i++) {
try {
bucket.upsert(document);
break;
} catch (TemporaryFailureException ex) {
try {
if (i == 5)
throw new TemporaryFailureException(ex);
System.out.println(“Esperando " + (i+1) + " min…”);
Thread.sleep(60000*(i+1));
continue;
} catch (InterruptedException e) { }
}
}
},
error → {System.out.println(error); });