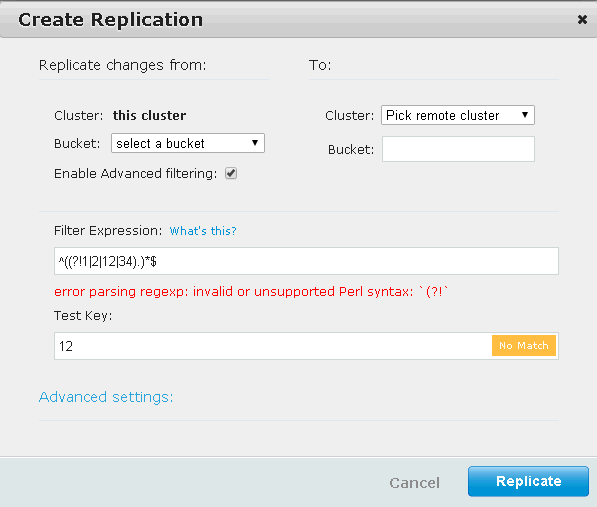
I am trying to exclude certain documents from being transported to ES using XDCR.
I have the following regex that filters ABCD and IJKL
Now, I want to use this regex in the XDCR filtering
^(?!.(ABCD|IJKL)).$
How do I exclude keys using regex?
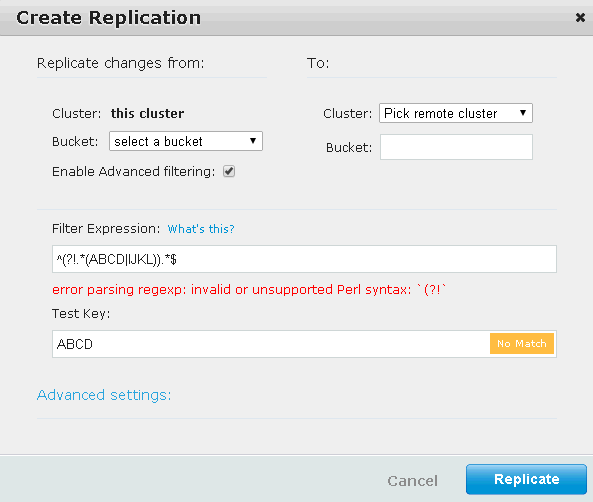
I am trying to exclude certain documents from being transported to ES using XDCR.
I have the following regex that filters ABCD and IJKL
Now, I want to use this regex in the XDCR filtering
^(?!.(ABCD|IJKL)).$
How do I exclude keys using regex?
This is because Go has poor support of regexps: https://golang.org/pkg/regexp/#pkg-overview
https://play.golang.org/p/eTrw3-QwXJ
package main
import (
"fmt"
"regexp"
)
func main() {
var validID = regexp.MustCompile(`^(?!.*(ABCD|IJKL)).*$`)
fmt.Println(validID.MatchString("ABCD"))
}
panic: regexp: Compile(`^(?!.*(ABCD|IJKL)).*$`): error parsing regexp: invalid or unsupported Perl syntax: `(?!`
goroutine 1 [running]:
panic(0x133400, 0x1050a130)
/usr/local/go/src/runtime/panic.go:500 +0x720
regexp.MustCompile(0x14ab5a, 0x15, 0x23ca0, 0x211d)
/usr/local/go/src/regexp/regexp.go:237 +0x1a0
main.main()
/tmp/sandbox786452339/main.go:9 +0x40It would be easier and more efficient to add common prefix or suffix to good keys, rather than using negative lookahead.
Thanks.
My keys do have prefix. Actually it is more like
CAR::12345
CAR::11933
BIKE::1233
BIKE::3131
BUS::3131
BUS::1313
Now, How can I filter Bike and car, if I have many not only BUS but many more types?
Enumerate them all? Or change application to use common prefix for everything except BIKE and CAR
OK, didn’t quite understand you.
Sorry.
Can you explain?
My application requests data from ElasticSearch.
But the data is entered to the CB.
The data is passed to the ES using xdcr…
I don’t want all data to be indexed.
I want to exclude some.
I am using prefix in my keys.
How can I filter the data in the XDCR?
I meant that you have to prepend another prefix when enter data into CB, for example:
0CAR::12345
0CAR::11933
0BIKE::1233
0BIKE::3131
1BUS::3131
1BUS::1313
1TRAIN::4213
1TRAIN::4242
In this case the regexp will be trivial and efficient: ^1