We are working through node failure testing in our dev environment, and found a very concerning/misleading notice. This testing in on a two-node cluster with the bucket in question set to have 1 replica.
Bucket document count before the hard failover
(We hard-failed the node by shutting down the server. This is purposely to simulate hardware failure)
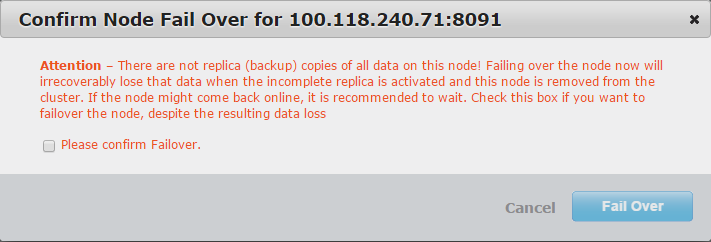
When we click the Fail Over button, the following notice appears:
After confirming this very nerve-racking warning message, the single node loaded it replica copies and all 3,112,468 documents were successfully load.
Isn’t that error entirely misleading? It leads you to believe that the replication engine was broken and wasn’t properly replicating the data, however this test proves that was not true. Is this a bug?
I believe the issue here is that the remaining cluster nodes cannot determine if there are sufficient replicas available due to one of the nodes being down (and unavailable) - as it doesn’t know exactly what sequence number the master node was up to before it went down.
Hence the cluster manager errs on the side of caution and shows the given message as it cannot prove it all data is available.
This seems a pretty reasonable approach to me - better to assume the worst (and tell the user that) than assume that all data can be retrieved and it turns out it can’t.
Finally - what operations were you performing on the cluster? If you were updating existing documents then it may turn out that you did loose data - while the document count may be consistent you may have lost some mutations to those documents.
Thanks Dribgy! We were not actively processing any data during the failure simulation, but that is something I want to understand in more depth at a later date. My goal with this simulation is to better understand the true fault-tolerance of Couchbase.
“***There are not replica (backup) copies of all data on this node!***” It’s tough to read-between-the-lines on that statement to me that is a statement of fact where the database system is saying we are definitely going to lose data. I understand erroring on the side of caution, but that statement immediately kills any credibility/trust in the fault-tolerance.
Is there any way to increase the fault-tolerance to where the database can be sure that we are -not- losing any data that’s persisted to disk? Would having a third node help it be able to determine if sufficient replicas are available? I understand that we may lose data for active writes in the write cache, but that’s an understandable risk with any application that caches writes.
We are assuming that writes in cache are immediately persisted to disk as soon as the disk resources are available. Meaning if the system has low load, small writes would be immediately persisted to disk. Is that correct, or do we need to programatically confirm that writes were persisted to disk?
Given you had just a two-node cluster this is a classic “split-brain” as the remaining node cannot reliably tell if:
a) The ‘other’ node actually died or
b) There was a network partition between the nodes (and hence the other node might still be up).
(and in scenario (b) the other node has the same quandary).
I sympathise that in this instance the message sounds pretty dire, but note there are a range of messages you’ll see depending on what knowledge the remaining cluster nodes have of the state of the system; some of which are less severe.
I would strongly recommend testing with at least three nodes - you’ll see in the documentation that we don’t recommend less than 3 nodes in any production deployment (to avoid the split-brain problem).
Nothing is never immediate :).
Mutation operations return to the client by default when the data has been accepted into the master nodes’ RAM cache; it will be (asynchronously) persisted to disk and replicated to peer nodes. If you require that a mutation has either been persisted to disk and/or replicated to a given number of nodes you should look at the PersistTo / ReplicateTo durability options for your selected SDK.
Thanks! Yes, our C# developer noted this option and is going to deploy it to our application. Thank you for confirming we are on the right track.
Ok, make sense. We are using three nodes in Production, but I was only using two nodes in my dev testing. So if we have three nodes with 1x replicas configured, you’re saying there’s a different message that will pop? I’ll queue that up as one of my test scenarios.
Thanks again for the active dialog on this, I really appreciate it.


 to me that is a statement of fact where the database system is saying we are definitely going to lose data. I understand erroring on the side of caution, but that statement immediately kills any credibility/trust in the fault-tolerance.
to me that is a statement of fact where the database system is saying we are definitely going to lose data. I understand erroring on the side of caution, but that statement immediately kills any credibility/trust in the fault-tolerance.