since upgrading to Couchbase lite for C from 2.8 to 3.0beta (using sg 2.8 for both scenarios), we face issues with our reverse proxy setup. When the client tries to pull a document with an attached blob the client says “connection reset by peer” and the reverse proxy says “The client unexpectedly aborted during data transfer”. However, if the mobile device connects directly to the sg without reverse proxy everything works fine. Are there any know issues, when upgrading to cbl3.0 and using haProxy as a reverse proxy?
Thank you very much.
I’m not aware any issues related to the reverse proxy. CBL uses WebSocket to communicate with SG. Some proxy such as NGINX requires some setup to work with WebSocket. I have never used haProxy so I can’t provide additional detail on the configuration.
What is the platform you are using CBL-C on?
CBL-C 3.0 will be the first release CBL-C, how do get the CBL-C prior 3.0 beta?
If you switch to use the prior version of CBL-C that you used before, will the problem go away? If it is going away, we can rule out proxy configuration problem.
Does the issue happen to all size of attachments?
Is there anything in the log (both CBL and SG log) when the issue happened?
Normally when investigating this kind of issue, we will need to see the actual packages sent b/w CBL and SG. You can use Wireshark to capture the packages sent b/w CBL and Reverse Proxy. If needed, you may need to check the packages b/w Reverse Proxy and SG as well. You have mentioned about timeout, I think we would need to who is not responding when pulling the attachment (CBL, Proxy, or SG).
We are using CBL-C on Android embedded in a Flutter Plugin.
The version, that was used before by the Flutter plugin was a pre-beta version.
Yes
I need to check. Currently, the size of the blobs is around 100kb
See the attachment. The SG simply says that the connection was closed by the client without any additional information. The proxy complains about an unusual disconnect with “The client unexpectedly aborted during data transfer”.
Yes, see the attachment and the additional error description
It seems to be an issue with TLS and not the proxy configuration. Everything works fine, if SSL-offloading is deactivated and no TLS is used over the proxy. As soon as we activate SSL offloading and move from ws:// to wss:// the connection becomes unreliable. The used SSL certificate is valid and also used for other HTTPS traffic.
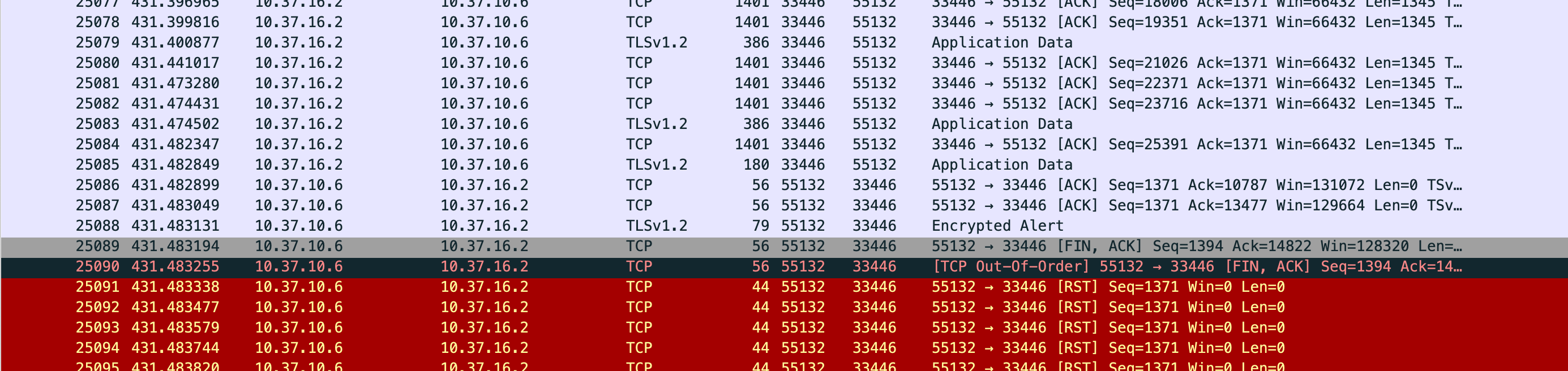
I attached some logs from the CBL logging and Wireshark. It is possible to see, that it is CBL (10.37.10.6) that requests to close the connection. Sometimes the connection is closed via FIN flag but sometimes directly via RST flag.
The console log shows, how CBL losses connection when trying to pull two documents with attached blobs. However, the connection with wss:// is unstable in general but documents with blob are nearly never pulled
The plugin used is cbl 1.0.0-beta.14 and the former CBL-C version (that worked with the same proxy and SG setup) was commit.
Can you double check the commit link again? It goes to the comparison page.
What is the keep-alive timeout set to the proxy? I don’t remember we have changed the default heartbeat interval (300 seconds) but the keep-alive timeout set to the proxy should be greater than the default heartbeat interval unless specified. But I’m not sure if this contributes to this blob issue or not as the issue happens during the active replication but it could contribute to the unstable connection when using the proxy.
Will the replication work properly if using SSL without the proxy?
The keep-alive value of the proxy is 350s. However, these disconnects and flowing reconnects happen more than ten times per minute. This is why I also thought, it should not contribute to the issue.
Good question! I will try to check that within the next day.
Would be happy if you have some ideas. Nevertheless, I will try to find some kind of MITM approach to provide you with cleartext logs.
I face the same issue if I connect directly via SSL (with an officially signed certificate) to the SG. The traffic behavior seems to be the same. I also attached some lines of the SG console output that is repeated after every reconnect around every two seconds (default reconnect time). So if I connect without TLS everything works fine. As soon as I switch to TLS, I get the described behavior.
FYI: If I go CBL <----- WS ------> Proxy <----- WSS ------> SG everything will work as well. So it seems like the CBL replicator does not enjoy WSS connections
When creating a new CBL database and starting the sync via the replicator, the connection gets lost several times even without blobs. From about 35 documents, each around 1kB, nearly all of them get synced within the first 20s. The last document is synced after 3-5 minutes later. As soon as the last document was synced, the connection seem to be stable without these connection losses every few seconds.
When replicating blobs, this behavior continues forever, as the blobs are never synced and the replicator never reaches this “idle” state.
Just to compare: If we sync without TLS connection, everything is done within a few seconds.
I need to try to reproduce the issue here. A some more questions:
Are you using 3.0 beta downloaded from Couchbase Website? or Did you build a binary by yourself from the code in Github? If you built one yourself, can you let me know the branch/commit you were using?
What platform are you testing?
Have you also tried using a self-signed certificate?
Can you share a full verbose log when connecting to the server without using the proxy?
I can replicate this problem with the following setup:
Self signed certificate
Sync Gateway Docker Image 3.0.0-beta02
No Couchbase Server, I use a walrus bucket instead
Couchbase Lite C SDK 3.0.0-beta02 prebuilt for macOS
These are the steps I take:
Open database A and B
Save 200 documents in database A. Each document has a blob of random data of 100KB.
Create replicator A for database A (push only, pinned self signed cert)
Start replicator A and wait for it to stop
Create replicator B for database B (pull only, pinned self signed cert)
Start replicator B and wait for it to stop
This sequence does not always produce network issues, but my observation is that more documents and larger blobs in those documents increase the likelihood.
Two lines from the Couchbase Lite logs that stuck out for me were:
12:11:32.569787| [TLS] ERROR: mbedTLS(C): mbedtls_ssl_flush_output() returned -26752 (-0x6880)
12:11:32.569965| [TLS] ERROR: mbedTLS(C): mbedtls_ssl_write_record() returned -26752 (-0x6880)
I looked at the SG log and I saw the following error:
cbl_e2e_tests-sync-gateway-1 | 2022-02-11T13:11:32.664Z [INF] WS: c:#083 Error: receiveLoop exiting with WebSocket error: unexpected EOF
cbl_e2e_tests-sync-gateway-1 | 2022-02-11T13:11:32.664Z [INF] WS: c:#083 Error: parseLoop closing socket due to error: io: read/write on closed pipe
Then:
cbl_e2e_tests-sync-gateway-1 | 2022-02-11T13:11:32.664Z [ERR] c:[1e4f78cc] Error during downloadOrVerifyAttachments for doc <ud>-ROB2ogRo0_VKGkU-9-BVos</ud>/1-dc7f00d1f0e816c4dbced5344dbd5de2aea8bb90: 400 Incorrect data sent for attachment with digest: sha1-IFoDhTd4vZcUaob9onc6unRzl5E= -- db.(*blipHandler).handleRev() at blip_handler.go:908
cbl_e2e_tests-sync-gateway-1 | 2022-02-11T13:11:32.664Z [ERR] c:[1e4f78cc] Error during downloadOrVerifyAttachments for doc <ud>-fYIfjuzAspPSZ1rtziOiio</ud>/1-7274ec9d4e8e70aaa3571fbf1e3c49eb8f38d130: 400 Incorrect data sent for attachment with digest: sha1-tbftci6WJgkLcD+NZc3pwj7fzOA= -- db.(*blipHandler).handleRev() at blip_handler.go:908
cbl_e2e_tests-sync-gateway-1 | 2022-02-11T13:11:32.664Z [ERR] c:[1e4f78cc] Error during downloadOrVerifyAttachments for doc <ud>-A-YD15JaKfqhhO28wgCrWT</ud>/1-3ee804c4069f6db26e05d067956752ce63ea69bb: 400 Incorrect data sent for attachment with digest: sha1-Ecmf3DaQOhVaJ7FPyQWDiF1bico= -- db.(*blipHandler).handleRev() at blip_handler.go:908
cbl_e2e_tests-sync-gateway-1 | 2022-02-11T13:11:32.665Z [INF] SyncMsg: c:[1e4f78cc] #83: Type:rev --> 400 Incorrect data sent for attachment with digest: sha1-IFoDhTd4vZcUaob9onc6unRzl5E= Time:57.968917ms
cbl_e2e_tests-sync-gateway-1 | 2022-02-11T13:11:32.665Z [INF] SyncMsg: c:[1e4f78cc] #57: Type:rev --> 400 Incorrect data sent for attachment with digest: sha1-Ecmf3DaQOhVaJ7FPyQWDiF1bico= Time:320.037292ms
cbl_e2e_tests-sync-gateway-1 | 2022-02-11T13:11:32.665Z [INF] SyncMsg: c:[1e4f78cc] #73: Type:rev --> 400 Incorrect data sent for attachment with digest: sha1-tbftci6WJgkLcD+NZc3pwj7fzOA= Time:202.736792ms
Based on Timestamp, client got POSIX 35 (EWOULDBLOCK / EAGAIN) error which causes the connection to be closed before the error happens on SG side when validating the attachment. I have chatted with a SG member and one theory is that the attachments sent to SG were truncated due to the closed socket. However, that shouldn’t cause any real issues (e.g. partial doc saved on SG side).
From the log, the pull replication also has the POSIX 35 errors which cause the stream / socket to close.
In general, the EWOULDBLOCK / EAGAIN error during read should be ignored and shouldn’t cause the stream / socket to close. I have realized that the fix for EWOULDBLOCK was not in the beta2. The next step would be trying out the binary including the fix. I will check if the binary is available to download or not, or you can build the binary yourself from the current release/lithium branch.
I understand that during write the server side can’t accept the data fast enough as it needs to decrypt blob data being transferred. I don’t have a good answer when the error happened during read. We are using poll() to know when the socket becomes readable, however, when trying to read from the socket, there was no data and EWOULDBLOCK is returned instead.